从巨潮资讯爬取上市公司公告
本文最后更新于 2022年10月16日 晚上
背景
最近闲着没什么事,就帮同学写了个爬取巨潮资讯上市公司公告的 python 脚本,根据公司的股票代码以及公告的日期自动下载公告( pdf 或者 html 格式)。
脚本开源在 cninfo-crawler。
刚开始本来想用 selenium 爬的,结果搞到一半发现完全没有反爬,就直接用 requests 库了。
爬取过程
我们先进入巨潮资讯主页,打开 F12 开发人员工具,再随便搜索一个公司的股票代码跟公告日期。
点击查询,然后关注右边开发者工具捕捉到的消息,将它们按照 Type 排序,我们要找的应该在 xhr 里面,而且方法应该是 POST。

一眼我们就发现 query 特别可疑,点开它看看。
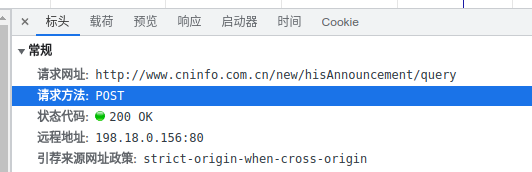
先看标头 POST 再看载荷
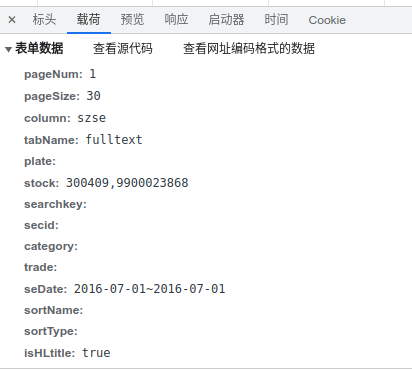
这个应该就是我们搜索的时候填的表单,stock 里面的 300409 就是股票代码, 但是那个 9900023868 是啥,不太懂。 seDate 就是我们查询的时间段。其他参数不用改。
获取下载链接
看一下预览,很明显 adjunctUrl 就是下载链接了,可惜这是个相对链接,
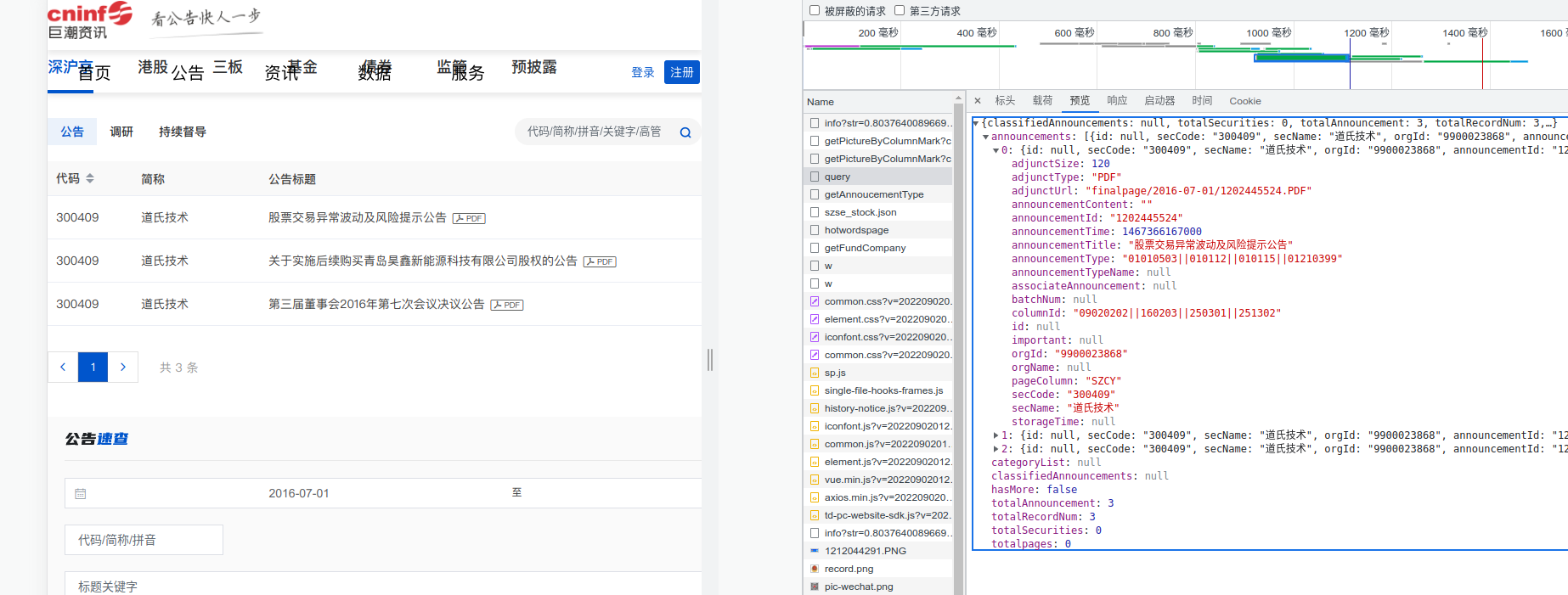
我们先点进去看一看,刚开始我尝试从 公告下载 捕获下载链接,但是事实证明完全没有用,后来发现可以点 全屏
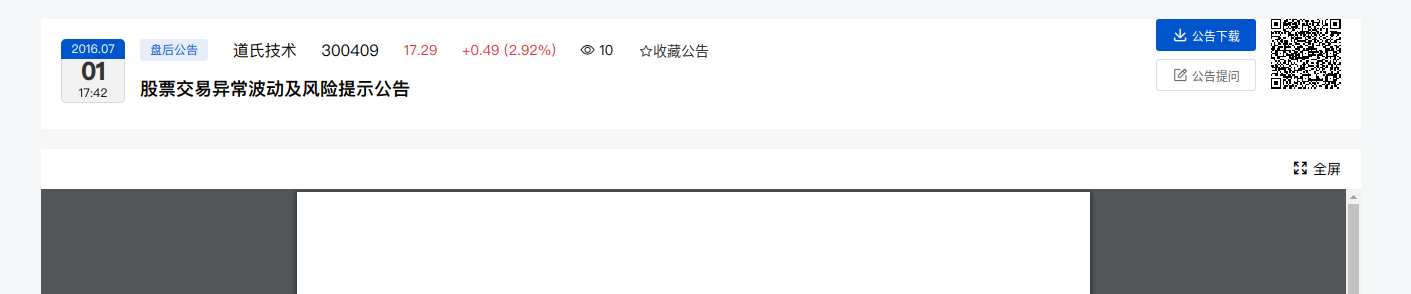
我们点进全屏,立马就发现 chrome 已经帮我们获取到了完整链接。
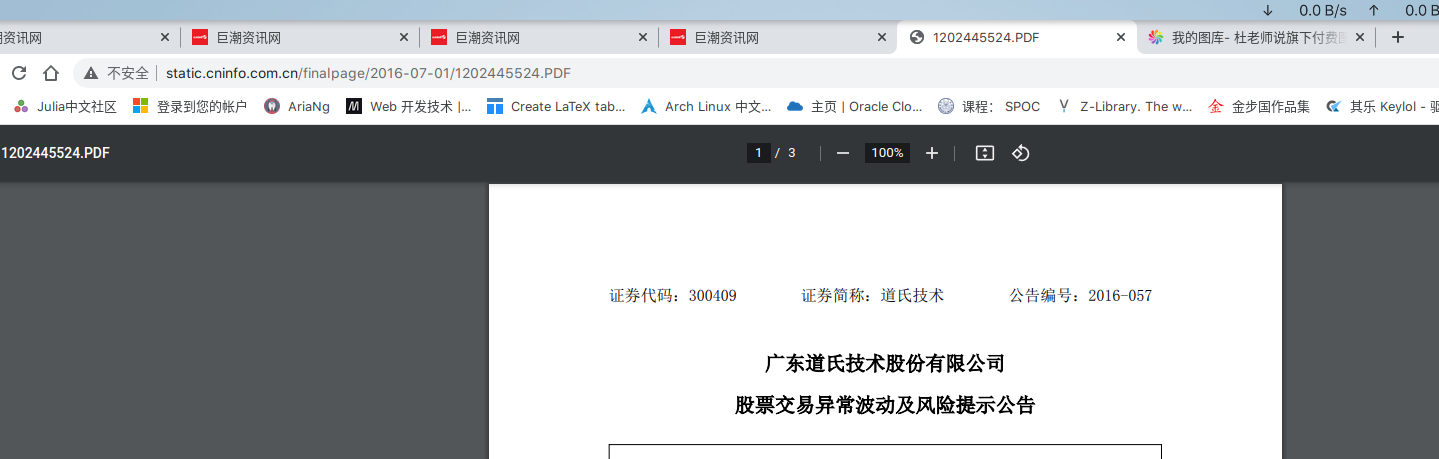
因此,完整链接就是 http://static.cninfo.com.cn/ 跟 adjunctUrl 拼接一下。
值得注意的是,并不是所有的文件都是 pdf,也有 html 所以如果要将下载下来的文件重命名的话,要处理下扩展名。
获取 orgId
这一部分我们说明一下那个神奇的数字 9900023868 怎么来的,因为单用 post 请求不带它的话根本不行,而这个数字每个股票代码不一样。
注意到 这里有一个 json 文件,我们点进去预览一下,发现有个 orgId,它就是了。
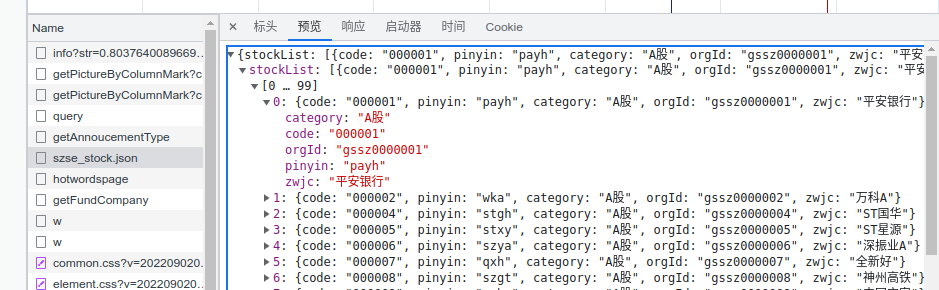
保险起见,我们找一下道氏技术的信息(或者搜索一个其他股票对一下)

没错,就是这样了。
因此,所有信息我们都有了。核心的下载代码如下
1 | |
其他的工作就是解析返回的json 与下载链接。本文就不再叙述了。
结语
巨潮资讯还是好爬的,完全没有做任何反爬。